中国开云体育一站式服务入口 CPU与GPU跑腹地 AI, 谁速率更快?


谜底并非“显卡好,CPU差”这样简便。
若是用户在腹地启动东说念主工智能,可能见过这样的提出:“买个好显卡”。但这到底是什么原理?CPU确切那么没用吗?谜底并非“显卡好,CPU差”这样简便。环节在于每个管制器若何管制东说念主工智能推理背后的数学运算,以及哪个管制器随机以充足快的速率管制数据,从而跟良策划进程。
东说念主工智能推理经过中究竟发生了什么?
当启动腹地 LLM 或图像模子时,硬件会反复奉行兼并件事:矩阵乘法。模子接收输入,将其更正为数字,然后将这些数字传递给各个层进行数十亿次的数学运算。硬件管制这些运算的速率越快,就能越快得到反应。
这是推理,即从考试好的模子中生成输出。用户并莫得考试任何东西。仅仅一一管制词元,进行数学运算。
CPU若何管制AI责任
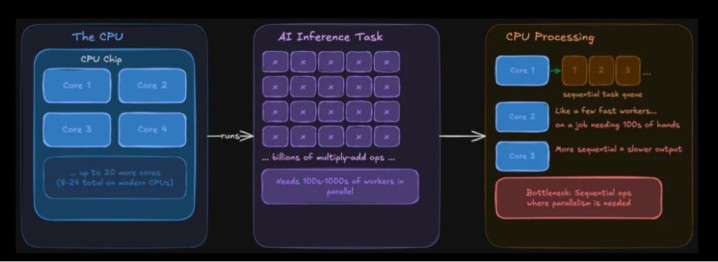
CPU 的盘算方针是四平八稳。它认真操作系统、浏览器标签页、文献系统,天然,它也能启动东说念主工智能模子。当代 CPU 领有多个中枢(滥用级芯片时时为 8 到 24 个),每个中枢王人功能重大且天真。
问题在于:东说念主工智能推理需要同期对海量数据奉行调换的操作。CPU 不错作念到这极少,但它管制这些操作的样貌更偏向于法例管制。这就像让几个速率极快的工东说念主去完成一项骨子上需要数百东说念主同期配合才智完成的责任。
话虽如斯,CPU并非完全无法胜任腹地AI任务。像llama.cpp这样的器用就特意针对CPU推理进行了优化,若是模子随机装进系统内存,那么完全不错只用CPU启动它。仅仅速率有时会彰着变慢,有时则否则,这取决于模子的大小。
GPU 若何管制 AI 责任
GPU 的盘算中枢便是并行策划。CPU 可能有 8 到 24 个中枢,而当代 GPU 则领稀有千个更小的中枢,这些中枢不错同期管制兼并问题的不同部分。这使得 GPU 在东说念主工智能模子所依赖的大限制数学运算方面发扬绝顶出色。
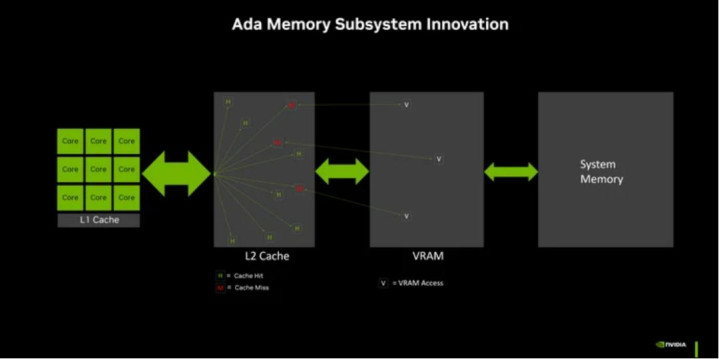
此外,GPU领有落寞的显存(VRAM),其带宽远高于系统内存。带宽至关难熬,它决定了数据传输到数千个中枢的速率。更高的带宽意味着更少的恭候时分和更多的策划时分。
具体到局部LLM推理,GPU的上风体当今两方面:并行管制智商和内存带宽。这两者王人获胜影响输出中每秒裸露的词元数目。
内存带宽
大大王人东说念主可能会感到讶异:关于局部 LLM 推理而言,原始策划智商时时不是死心身分,内存带宽才是。
在推理经过中,需要从内存中读取每个生成的词元对应的模子权重。若是内存无法充足快地将数据传输给管制器,那么岂论有若干个中枢王人于事无补,它们只会闲置恭候。
这便是为什么显存带宽如斯难熬。典型的DDR5系统内存设置可能提供50-90 GB/s的带宽。而像RTX 5090这样的当代GPU不错提供卓绝1000 GB/s的带宽。这但是数目级的差距。
若是模子完全不错放入显存中,开云体育仅凭这极少,GPU 上的推理速率真实老是比 CPU 上的推理速率更快。
何时仅使用 CPU 才是聪敏之举
GPU并非老是最好礼聘。在某些情况下,使用CPU启动才是正确的礼聘:
你启动的是一个袖珍模子(3B 参数或更少),速率各异真实难以察觉。
您的显卡不兼容,或者您的显卡显存不及以救援该型号。
你思应用通盘系统内存(时时比显存大得多)以较慢的速率启动更大的模子。
你使用的是条记本电脑或台式机,而GPU功耗或发烧量是一个需要研究的问题。
开云app在线体育官网由于量化技巧(缩小模子精度以减少内存占用)以及针对量化技巧优化的框架,CPU推感性能得到了显耀提高。在配备32GB内存的当代CPU上启动量化后的70亿模子,足以胜任好多任务。
若是您的模子太大,超出显存容量,但您仍然但愿赢得 GPU 加快,大大王人腹地 LLM 器用王人救援部分卸载。这意味着模子的某些层在 GPU 上启动,而其余层在 CPU 上启动。
这是一种量度:天然能赢得一些 GPU 的速率上风,但 CPU 密集型层会成为瓶颈。VRAM 中能容纳的层越多,速率就越快。但若是惟一少数几层最终在 GPU 上启动,那么数据在 GPU 和 GPU 之间往来传输的支出骨子上可能会使其速率比纯 CPU 推理还要慢。
教训握法是:若是至少一半的模子无法放入显存中,那么最好完全在 CPU 上启动它,从而幸免加多复杂性。
NVIDIA 与 AMD 在腹地 AI 范畴的竞争
NVIDIA 现时在腹地 AI 范畴占据主导地位,这主要归功于 CUDA。真实统共 AI 器用王人基于 CUDA 这个私有的策划框架构建。若是您在 Windows 系统上使用 LM Studio、Ollama 或 llama.cpp,NVIDIA GPU 将为您带来最畅通的体验,并将故障排责难任量降至最低。
AMD正在蹈厉奋发。ROCm(AMD对标CUDA的技巧)取得了显耀进展,像Ollama这样的器用也明确救援Windows上的AMD Radeon GPU。但现时的生态系统仍然较为有限,证据你使用的GPU型号和器用的不同,你可能会遭遇兼容性问题。
若是购买显卡的方针是为了腹地AI,那么现时NVIDIA显卡是更适当的礼聘。若是你一经领有AMD显卡,那么也实足值得一试,但最好先搜检一下你所用器用的文档,说明它救援的型号。
*声明:本文系原作家创作。著作内容系其个东说念主不雅点,本身转载仅为共享与究诘,不代表本身讴歌或认可,如有异议,请干系后台。
思要获取半导体产业的前沿洞见、技巧速递、趋势领路中国开云体育一站式服务入口,存眷咱们!